
Abstract
Safety in goal directed Reinforcement Learning (RL) settings has typically been handled through constraints over trajectories and have demonstrated good performance in primarily short horizon tasks. In this paper, we are specifically interested in the problem of solving temporally extended decision making problems such as robots cleaning different areas in a house while avoiding slippery and unsafe areas (e.g., stairs) and retaining enough charge to move to a charging dock; in the presence of complex safety constraints. Our key contribution is a (safety) Constrained Search with Hierarchical Reinforcement Learning (CoSHRL) mechanism that combines an upper level constrained search agent (which computes a reward maximizing policy from a given start to a far away goal state while satisfying cost constraints) with a low-level goal conditioned RL agent (which estimates cost and reward values to move between nearby states). A major advantage of CoSHRL is that it can handle constraints on the cost value distribution (e.g., on Conditional Value at Risk, CVaR) and can adjust to flexible constraint thresholds without retraining. We perform extensive experiments with different types of safety constraints to demonstrate the utility of our approach over leading approaches in constrained and hierarchical RL.
- We provide a scalable constrained search approach suited for long horizon tasks within a hierarchical RL set-up.
- We are able to handle rich percentile constraints on cost distribution.
- The design of enforcing the constraints at the upper-level search allows fast recomputation of policies in case the constraint threshold or start/goal states change.
- Mathematical guarantee for our constrained search method. Finally, we provide an extensive empirical comparison of CoSHRL to leading approaches in hierarchical and constrained RL.
Problem Formulation
We are aiming to solve the Constrained Reinforcement Learning problem which can be formalized as:
$$ \begin{align*} \max_{\pi} & V^{\pi}(s_O,s_G) \\ s.t. \; & V_c^\pi(s_O,s_G) \leq K \\ & V^\pi(s_O,s_G) = \mathbb{E} \left[\sum_{t=0}^T r^t(s^t,a^t) \mid s^T = s_G, s^0 = s_O \right] \\ & V^\pi_c(s_o,s_G) = \mathbb{E}\left[\sum_{t=0}^T c^t(s^t,a^t) \mid s^T = s_G, s^0 = s_O \right]. \end{align*} $$
However, in the above, the constraint on the expected cost value is not always suitable to represent constraints on safety. E.g., to ensure that an autonomous electric vehicle is not stranded on a highway, we need a robust constraint that ensures the chance of that happening is low, which cannot be enforced by expected cost constraint. Therefore, we consider a cost constraint where we require that the CVaR of the cost distribution is less than a threshold. With this robust variant of the cost constraint (also known as percentile constraint), the problem that we solve for any given \(\alpha\) is:
Note that \(\alpha\) is risk neutral, i.e. \( CVaR_{1}(\mathbf{V}_c^\pi) = \mathbb{E}[\mathbf{V}_c^\pi] = V_c^\pi \), and \(\alpha\) close to 0 is completely risk averse.
$$ \max_{\pi} V^{\pi}(s_O,s_G) \quad \text{s.t.} \quad CVaR_{\alpha}(\mathbf{V}_c^\pi) \leq K \tag{1} $$
Method
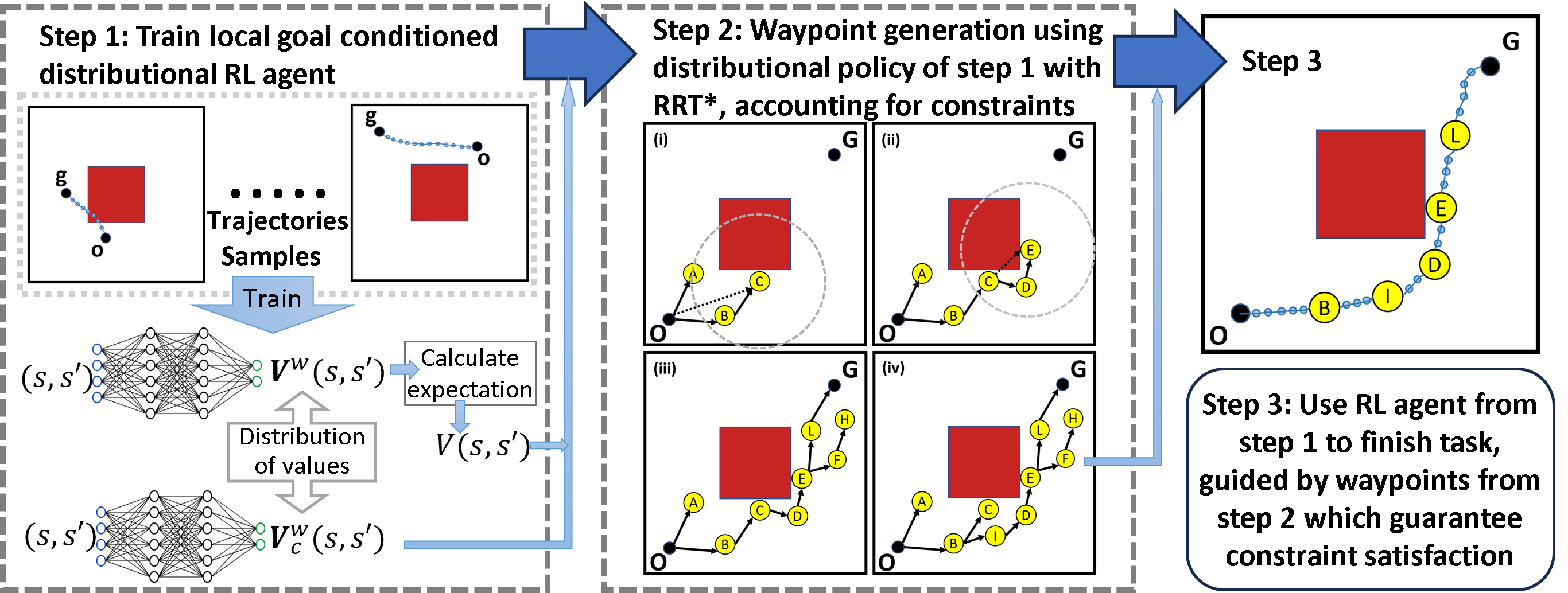
Step 1: Train a local goal-conditioned RL agent using multiple randomly selected (o, g) (o is start, g is goal) pairs in a constrained environment (top part). The red square indicates a high-cost region. The learning is local and hence the goal will be unreachable if it's not "near" to the start. In this step, the local value function V and the cost function Vc are learned.
Step 2: Generate waypoints guided by V and Vc using the proposed ConstrainedRRT* algorithm
- The search samples state C, and O is not within the dashed circle of "near" states. Although both A and B are within the circle, the path from O to C via B is better as V(O,B) + V(B,C) < V(O,A) + V(A,C) using low-level agent's V function. So, edge (B, C) is added to the tree.
- For new sample E, E is "near" from C and D, but the edge (C, E) is not valid because of cost constraint CVaRα(Vc(O, B) + Vc(B, C) + Vc(C, E)) > K.
- A path (O, B, C, D, E, L, G) within the cost constraint is found.
- As the number of sampled states increases, a better path (O, B, I, D, E, L, G) is found.
Step 3: Leveraging the waypoints from step 2, the pre-trained goal-conditioned RL agent completes the task.
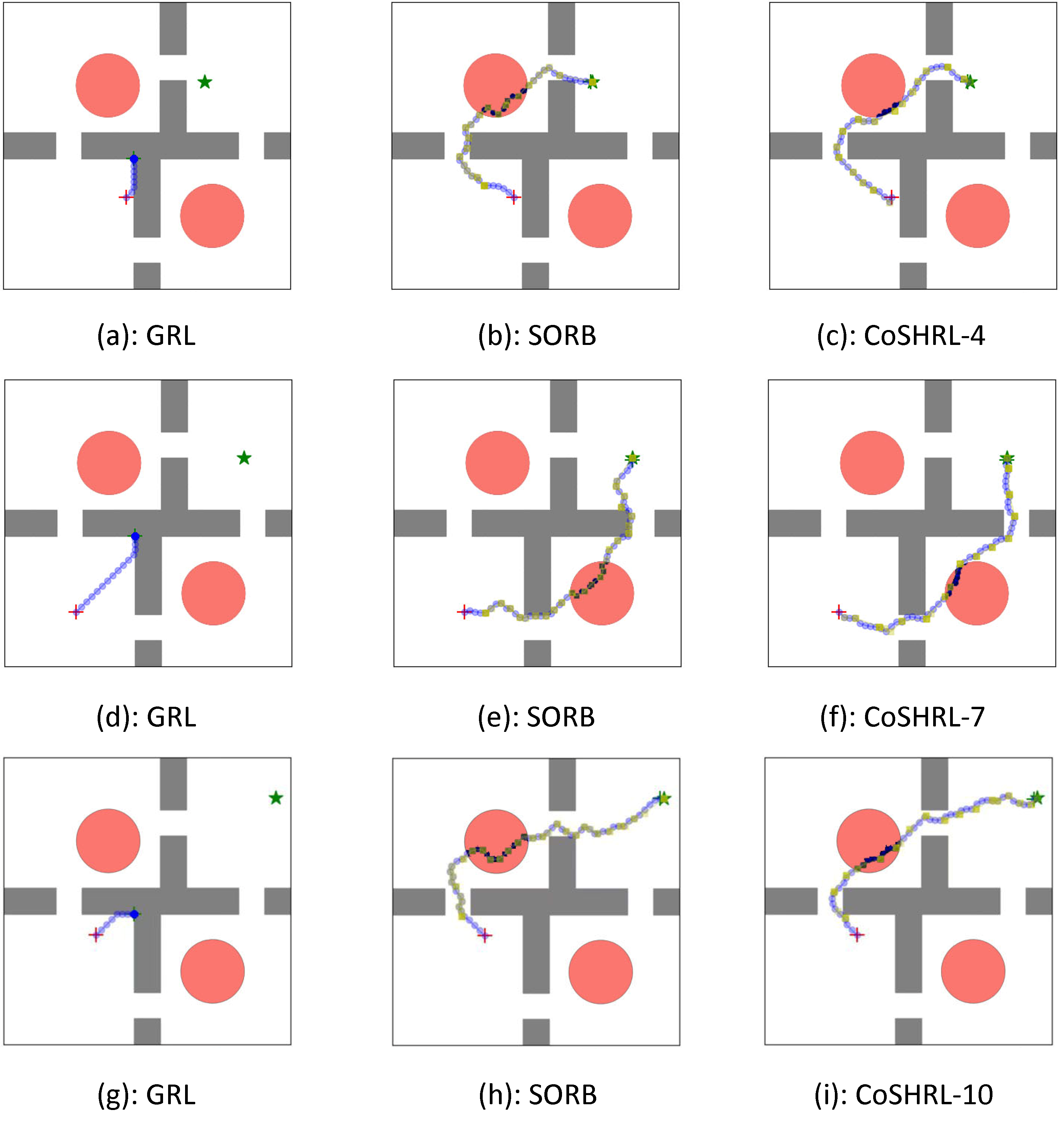
More Results
We test our method on a 2D navigation task and an image-based navigation task. Our method is comparable to non-constrained RL baseline methods in terms of success rate and length of the trajectories environments without constrains. And our method outperforms the constrained RL baseline methods in terms of constraint violation, success rate, and length of the trajectories.
Acknowledgements
This research/project is supported by the National Research Foundation Singapore and DSO National Laboratories under the AI Singapore Programme (AISG Award No: AISG2-RP-2020-017)BibTeX
@article{lu2023conditioning,
title={Handling Long and Richly Constrained Tasks through Constrained Hierarchical Reinforcement Learning},
author={Lu, Yuxiao and Varakantham, Pradeep and Sinha, Arunesh},
journal={arXiv preprint arXiv:2302.10639},
year={2023}
}